This document will go through how mdzk operates and how you can use it in your workflows. Currently, it is quite limited, as mdzk is still under heavy development. If you have any suggestions to things that should be added, open an issue on our GitHub describing it and mark it with the documentation label. Any contributions are of course welcome.
You can install mdzk from multiple package managers:
| Source | Installation command |
|---|---|
| AUR (with Paru) | paru -S mdzk |
| Crates.io | cargo install mdzk |
| Homebrew | brew install mdzk |
| Nix | nix run nixpkgs#mdzk -- <command> |
There is also a range of pre-built binaries available through the release page on GitHub.
If you want the latest and greatest, you can build mdzk from scratch by cloning the repo and building using Rust tooling:
$ git clone https://github.com/mdzk-rs/mdzk.git
$ cd mdzk
$ cargo build --releaseAn mdzk binary for your system will now be available in ./target/release.
At it’s core, mdzk operates on a vault with notes containing optional internal links. Let’s unpack these terms:
In the filesystem, a vault is represented by directory, the notes being Markdown-files. mdzk takes a directory as input, recursively finds any Markdown-files in it and loads each of them as a node in the graph. It then parses every file and establishes edges between the nodes based on the links contained in it.
The vault data structure is a very efficient and useful concept in dealing with notes and their relation together. mdzk models a vault as an adjacency matrix and does custom hashing on each note to obtain unique note IDs. This means that we get incredibly fast lookups on note adjacencies.
As a user, you can think of a vault simply as a directory with a bunch of Markdown-files. You may structure this directory however you want and include any other filetypes - mdzk does not care. The major difference to keep in mind, is that a vault does not include the notion of any hierarchy. You may bury a note in a subdirectory of a subdirectory of a subdirectory if you want, mdzk will still handle it the same way as a note placed in the root.
Consider the vault with the following tree:
.
├── sub
│ ├── subsub
│ │ └── note-0.md
│ └── note-1.md
└── note-2.mdProducing a visualization of this vault, might look like this:
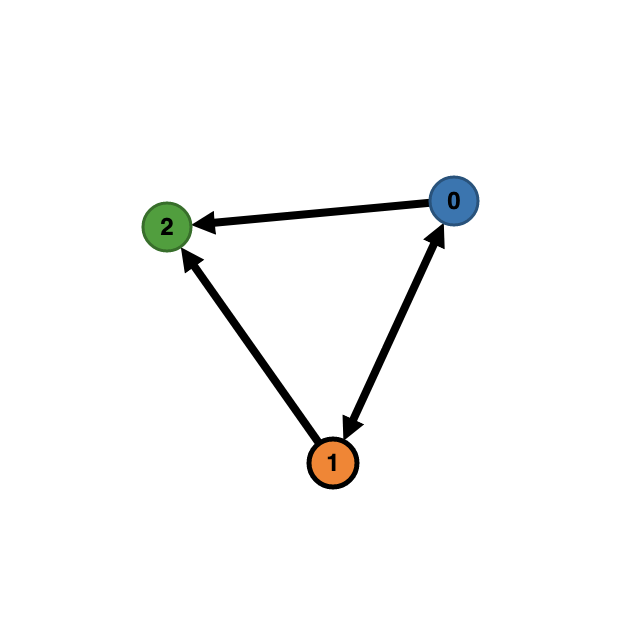
As you can see, the paths were totally ignored; internal links are the only constructs that define the vault structure. The filepaths are still stored as metadata, so custom workflows using directory hierarchies can still be made if one wants.
{
"notes": [
{
// A unique ID, formatted as a hex digit
"id": string,
// The given title, taken from the filename or
// explicitly set via front matter
"title": string,
// A relative path from the vault root to the note
"path": string | null,
// A set of tags set for the note
"tags": [string],
// RFC3339-formatted datestring
"date": string | null,
// The original content of the source file that
// produced this note
"original-content": string,
// The content of the note. All internal links are
// converted to CommonMark and the front matter
// is stripped.
"content": string,
// A set of note IDs, each representing an
// outgoing internal link
"links": [string],
// A set of note IDs, each representing an
// incoming internal link
"backlinks": [string]
}
],
// Not yet implemented: "tags": []
}